專有名詞介紹
Regression: 要找的函式輸出為一個數值
Classification: 先準備好一些選項,輸入所要的資料,輸出則會是選項中的其中一個。
Structure Learning : 函式所輸出的東西是一個有結構的物件。ex:機器畫一張圖,寫一篇文章
機器學習三步驟
- 找一個帶有未知參數的函式: 先預測可能會影響的參數

2. 定義LOSS:
LOSS : 一個函式,輸入式MODEL裡的參數,輸出的值代表這組參數(輸入的)好還是不好,可以透過帶入估算值和實際值來做LOSS的計算。

上述將b w 帶入0.5 1 去估算結果,在與實際值相減後所得e,全部的e平均下來得到Loss。Loss愈小愈好
3. 解最佳化問題(Optimization)

找一個w,b使得Loss最小。使用的方式為Gradient Descent(課堂上唯一會用到的方式)。
Gradient Descent:

先假設只有一個未知參數W,將error surface畫出來(即在所有w的值畫出其對應的L)。
隨便挑選一個w0,然後看其error surface之切線斜率,如果是負的,則增加w,如果是正的則減少w

其w所移動之大小,根據learning rate來做決定。
Hyperparameter: 是自己要設定的參數

走到loss很低或是loss不再變動,不代表找到最低Loss,因此有local、global之分。
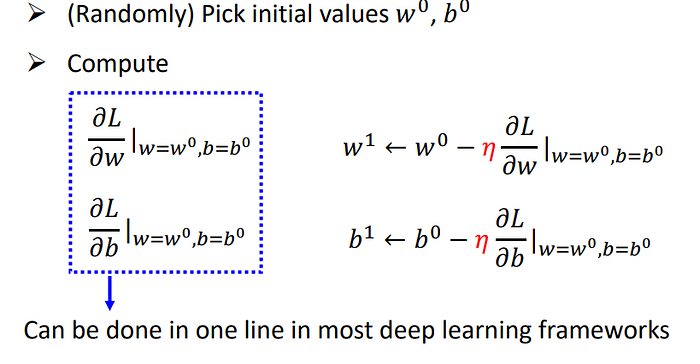
一個參數推廣到兩個參數,一樣的方式,一樣操作。
以上的Model 為 Linear Model,但Linear Model似乎太過簡單。
因為Linear似乎太過簡單,為了畫出更複雜的圖形,可利用多個藍色線段組合成紅色線段。

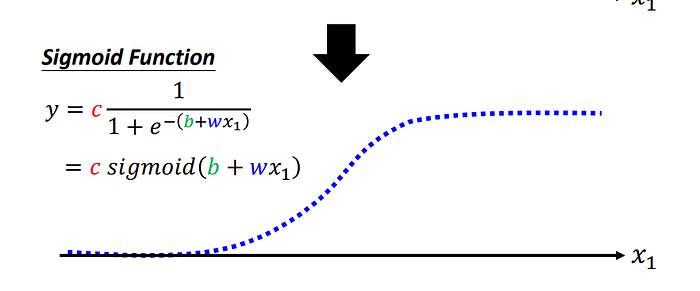
藍色function是如何寫出來呢?
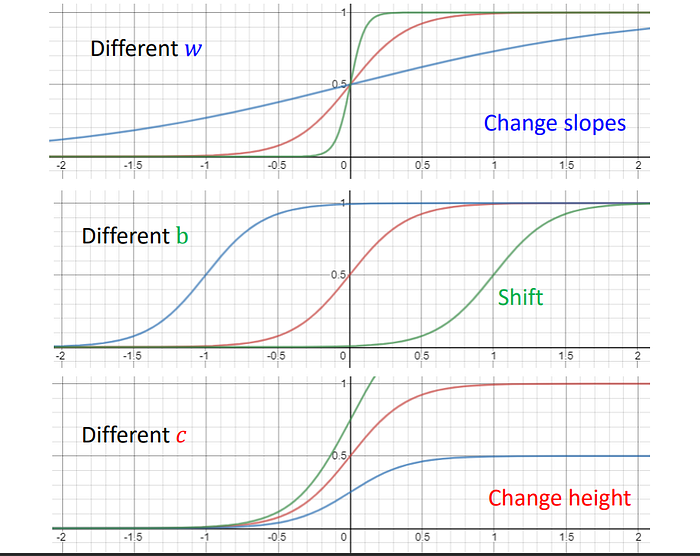
上述函式,改w則會改變斜率、改b會改位移(左右移動)、改c改變高度。
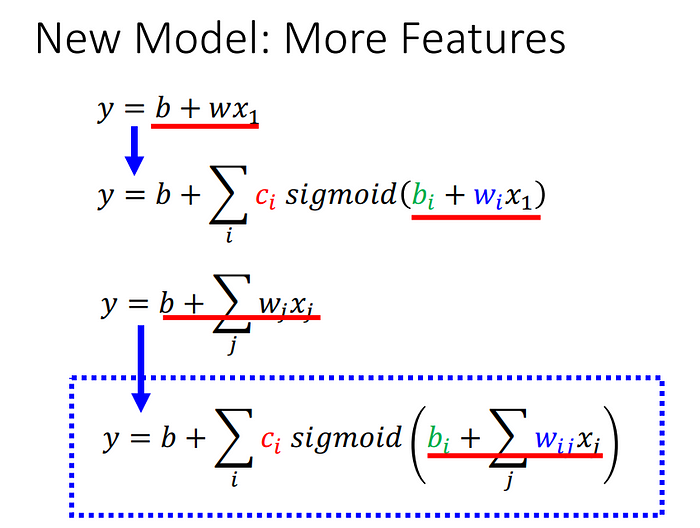
因此可以做延伸:
從一開始的w、b是參數但是由多個sigmoid function合成一個圖像,之後變成多個w當作參數也是由多個sigmoid function合成圖像。
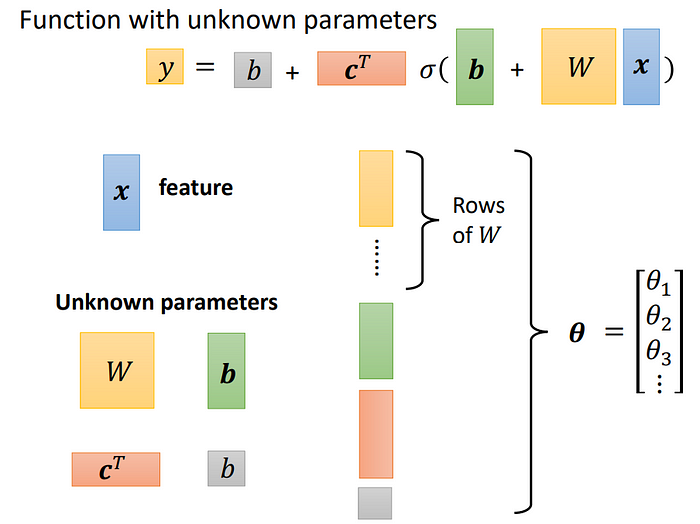
而上述的Θ向量包含了所有的未知參數,這些參數是LOSS的輸入,在按照Gradient discent的方式算Loss。
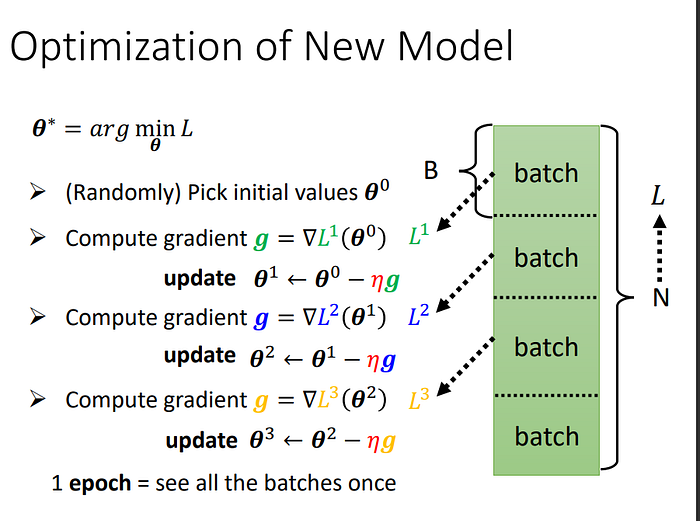
在大筆資料中找loss,首先會先將全部Data分成多個batch,再算完一個batch之後才會更新gradient,依序根據batch更新gradient。把所有的batch都看過一遍稱作epoch,每次更新參數稱作update。
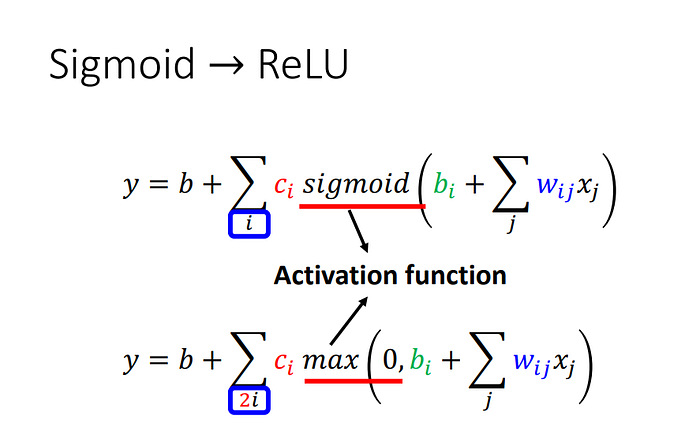
Rectified Linear Unit(ReLU)

在某個區間段會是0,將上述兩者加起來可成為一個hard sigmoid。
Overfitting:
在訓練資料表現好,在測試資料表現差
#以上為參考李宏毅老師講義自己做筆記使用